













Last week, PensionBee’s CEO Romi laid out our argument for why unnecessary delays to the launch of commercial Pensions Dashboards would have a detrimental effect on the consumers these dashboards are supposed to help. In this post, I take a look at the proposed technical architecture for the overall system and conclude that an approach based on familiar design patterns, open APIs and mechanisms for accessing data directly from providers is preferable to the centralised model described in the feasibility study.
The study lays out three architectural design principles which are intended to promote the best outcome for consumers:
- put the consumer at the heart of the process by giving people access to clear information in one place online;
- ensure that individuals’ data are secure, accurate and simple to understand – minimising the risks to the consumer and the potential for confusion; and
- ensure that the individual is always in control over who has access to their data.
In service of these goals, the system is designed to route all pension provider data through a single “Pension Finder Service” (PFS), which would be industry funded. The PFS would be responsible for handling requests from dashboards, making sure these are authenticated via a separate Identity Service, and then forwarding the requests on to the pension providers, who would send their data back to the dashboard initially making the request. Individuals would grant consent to advisors and other trusted third parties to have delegated access to their data.
So, what are the problems?
There are three main problems with the approach that the government has proposed. Firstly, the study takes a naive and narrow view of what constitutes a dashboard, drawing its technical conclusions from a use case that focuses on displaying to a single individual a read-only summary of information about their pensions. This view of how pension data will be used contains a self-defeating level of expectation about the innovation that will be produced as a result of wide access to this data. We just can’t know what a “dashboard” will do and be in 2021, when this is likely to be rolled out. Technical design principles that flow from this narrow expectation, such as preventing dashboards from storing any data, and not allowing for APIs that write data back to pension schemes (e.g. to set up new contributions or change your personal details), erect barriers to future consumer-friendly innovation. A lesson from Open Banking, and the history of Open Data more generally, is that you cannot plan for the myriad uses of data once you have put it out into the wild, so you should focus your attentions on designing a secure and consistent model for data access and exchange, and sufficient governance and technical standards to ensure all parties can be trusted to the extent they need to be.
A distributed model is more fault tolerant than a centralised system
The second problem is the restriction to only having a single PFS connecting to provider APIs. The justification for this is partly security and partly cost. The claim that this produces superior security seems to rest on a flawed assumption that the security of a system is defined by the number of participants in the system; in fact, it rests on the security of the weakest connection. In a model with a single PFS centralising all communication between providers and consumers, the PFS is a single point of failure. Compromising the PFS would mean either unacceptable downtime or redirection of the flows of personal information and pension information by hackers. The architecture of the internet itself shows that a distributed model is more fault tolerant than a centralised system. If consumers, dashboards and any intermediary PFSs are all treated as equally untrusted third parties by the providers, there is a higher chance that the security of these links will be strong. Conversely, in a system where there is a trusted pool of providers connecting to a single PFS, the chances for bugs and vulnerabilities to go undetected until it is too late is much higher.
How is an ISP really any different to an additional PFS?
The suggestion that a single PFS is the lowest cost way to set up the system is a red herring. We should be looking for ways that building a service that aggregates pension data produces economic value and therefore pays for itself. If the providers have to build APIs to connect to the PFS, there is no technical reason why they cannot subsequently connect to commercial PFS/dashboards directly, and there will be an economic incentive for this opening up to innovative market solutions – this trumps a model where the industry is forced to pay for a single service. The suggestion that a single PFS would be cheaper ignores the very likely possibility that the market would deliver cheaper, more effective solutions. As a side point, restricting the system to a single PFS is inconsistent with a suggestion that providers who cannot build their own APIs make use of “Integrated Service Providers” (ISP) - technically speaking, how is an ISP really any different to an additional PFS?
This is worse than reinventing the wheel
The third major issue with the proposed design is that it is unfamiliar and overly complex, without any clear economic gain arising from this. It is not clear how you would implement a system where the PFS handles an initial request from a dashboard but then has no knowledge of the data being passed back, without some serious compromises being made around peer-to-peer security. This is not how Open Banking works for example, where data flow back to whichever authenticated party made the request. This is worse than reinventing the wheel, so why do it? At a high-level, we have a set of consumers accessing personal finance data from a disparate set of sources, which is a problem that is currently being admirably solved by the Open Banking Implementation Entity, and has already attracted a huge amount of funding, experimentation, testing and development of genuinely interesting and innovative use cases, that the underlying technical framework encourages. If key design principles are to keep security high and costs low, you want a system that builds on what others have done and reuses common data exchange mechanisms and protocols. To protect consumers further, you want them to find data access and sharing systems familiar too, so they can rely on behaviours they have learnt for keeping their personal data secure.
The solutions
We see three solutions to the problems stated above. First of all, relax statements about arbitrary and limiting use cases and data storage rules, focusing instead on data exchange standards, good governance and a model that encourages innovation. Where innovations can be introduced that increase competition and justify investment in good APIs, there should not be barriers to this. If a provider can support write APIs to allow information to flow back into their pension schemes, that will allow them to differentiate themselves, increasing competition in the sector.
Secondly, providers should be required to open up API connections to their data and treat all consumers of those APIs equally (see diagram below). The government’s focus should be on making sure that any third party has a consistent and secure means to access this data on behalf of an individual, leaving the market to sort out the rest. Make use of existing regulatory devices for assuring third parties, such as requiring ISO certification before granting regulatory permissions, and reminding pension providers of their obligations under GDPR to execute comprehensive Data Processing Agreements with the third parties consuming and processing their customers’ data.
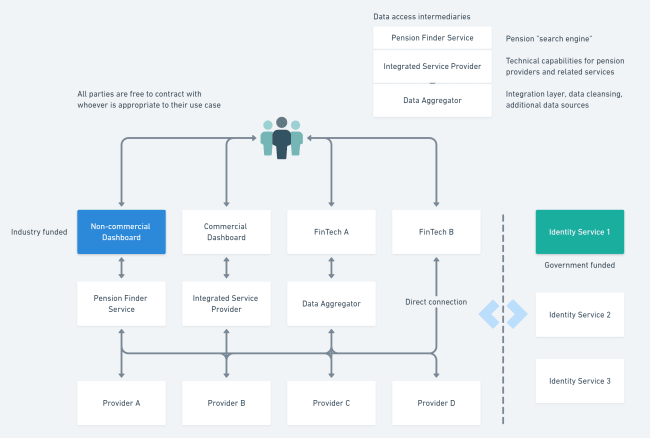
Lastly, explicitly build on the work of the Open Banking Implementation Entity, in terms of the standards used in data exchange, authentication systems, protocols, and governance. Industry-wide groups such a FDATA have completed research into the consequences of moving to an API-driven economy, and this has value for the pensions industry, so this should be incorporated into our starting point. There are a lot of technical ingredients out there to reuse: OpenID Connect for authentication; OAuth 2.0 for authorization; the Open Banking API Standard for consistent data exchange; and as a model for ISPs and PFSs, we have new companies such as TrueLayer and Token, and the established membership of FDATA, who have plenty of commercial experience relevant to these challenges. Only by bringing all financial services participants under a common technical umbrella can we put behind us the fragmentation of the industry’s past, and move to a world where consumer-focused innovation can flourish on top of open standards – much like the internet itself.
The last piece in the puzzle is the question of the right model for governance of this ecosystem, and is this subject that Clare Reilly, PensionBee’s Head of Corporate Development, will turn to in the next post of this series.
Period | Market Event | FTSE World TR GBP (%) | 4Plus Plan (%) |
|---|---|---|---|
4Plus Plan’s inception – 6 Sept 2013 | QE Tapering, China Interbank Crisis and its aftermath | -5.44 | -2.41 |
3 Oct 2014 – 15 May 2015 | Oil price drop, Eurozone deflation fears & Greek election outcome | -5.87 | -1.77 |
7 Jan 2016 – 14 Mar 2016 | China’s currency policy turmoil, collapse in oil prices and weak US activity | -7.26 | -1.54 |
15 June 2016 – 30 June 2016 | BREXIT referendum | -2.05 | -1.07 |




